Summary
This is a followup to an earlier post about using Python to measure the “Anglo-Saxonicity” of a text. I’ve used my code to analyze the Baby version of the British National Corpus, and I’ve found some interesting results.
How to Measure Anglo-Saxonicity – With a Ruler or Yardstick?
Introduction
Thanks to a suggestion from Ben Sizer, I decided to analyze the British National Corpus. I started with the ‘baby’ corpus which, as you might imagine, is smaller than the full corpus.
It’s described as a “100 million word snapshot of British English at the end of the twentieth century“. It categorizes text samples into four groups: academic, conversations, fiction, and news. Below are stack plots showing the percentage of Anglo-Saxon, non-Anglo-Saxon, and unknown words for each document in each of the four groups. The Y axis shows the percentage of words in each category. The numbers along the X axis identify individual documents within the group.
I’ve deliberately given the charts non-specific names of Group A, B, C, and D so that we can play a game. :-)
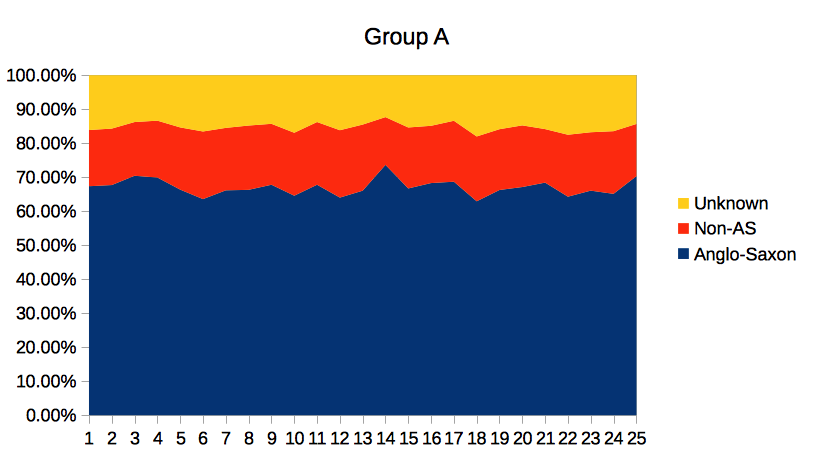



Before we get to the game, here’s the averages for each group in table form. (The numbers might not add exactly to 100% due to rounding.)
| Anglo-Saxon (%) | Non-Anglo-Saxon (%) | Unknown (%) | |
|---|---|---|---|
| Group A | 67.0 | 17.7 | 15.3 |
| Group B | 56.1 | 25.8 | 18.1 |
| Group C | 72.9 | 13.2 | 13.9 |
| Group D | 58.6 | 22.0 | 19.3 |
Keep in mind that “unknown” words represent shortcomings in my database more than anything else.
The Game
The Baby BNC is organized into groups of academic, conversations, fiction, and news. Groups A, B, C, and D each represent one of those groups. Which do you think is which?
Click below to reveal the answer to the game and a discussion of the results.
Answers
| Anglo-Saxon (%) | Non-Anglo-Saxon (%) | Unknown (%) | |
|---|---|---|---|
| A = Fiction | 67.0 | 17.7 | 15.3 |
| B = Academic | 56.1 | 25.8 | 18.1 |
| C = Conversations | 72.9 | 13.2 | 13.9 |
| D = News | 58.6 | 22.0 | 19.3 |
Discussion
With the hubris that only 20/20 hindsight can provide, I’ll say that I don’t find these numbers terribly surprising. Conversations have the highest proportion of Anglo-Saxon (72.9%) and the lowest of non-Anglo-Saxon (13.2%). Conversations are apt to use common words, and the 100 most common words in English are about 95% Anglo-Saxon. The relatively fast pace of conversation doesn’t encourage speakers to pause to search for those uncommon words lest they bore their listener or lose their chance to speak. I think the key here is not the fact that conversations are spoken, but that they’re impromptu. (Impromptu if you’re feeling French, off-the-cuff if you’re more Middle-English-y, or extemporaneous if you want to go full bore Latin.)
Academic writing is on the opposite end of the statistics, with the lowest portion of Anglo-Saxon words (56.1%) and the highest non-Anglo-Saxon (25.8%). Academic writing tends to be more ambitious and precise. Stylistically, it doesn’t shy away from more esoteric words because its audience is, by definition, well-educated. It doesn’t need to stick to the common core of English to get its point across. In addition, those who shaped academia were the educated members of society, and for many centuries education was tied to the church or limited to the gentry, and both spoke a lot of Latin and French. That has probably influenced even the modern day culture of academic writing.
Two of the academic samples managed to use fewer than half Anglo-Saxon words. They are a sample from Colliding Plane Waves in General Relativity (a subject Anglo-Saxons spent little time discussing, I’ll wager) and a sample from The Lancet, the British medical journal (49% and 47% Anglo-Saxon, respectively). It’s worth noting that these samples also displayed highest and 5th highest percentage of words of unknown etymology (26% and 21%, respectively) of the 30 samples in this category. A higher proportion of unknowns depresses the results in the other two categories.
Fiction rests in the middle of this small group of 4 categories, and I’m a little surprised that the percentage of Anglo-Saxon is as high as it is. I feel like fiction lends itself to the kind of description that tends to use more non-Anglo-Saxon words, but in this sample it’s not all that different from conversation.
News stands out for having barely more Anglo-Saxon words than academic writing, and also the highest percentage of words of unknown etymological origin. The news samples are drawn principally from The Independent, The Guardian, The Daily Telegraph, The Belfast Telegraph, The Liverpool Daily Post and Echo, The Northern Echo, and The Scotsman. It would be interesting to analyze each of these groups independently to see if they differ significantly.
Future
My hypothesis that conversations have a high percentage of Anglo-Saxon words because they’re off-the-cuff rather than because they’re spoken is something I can challenge with another experiment. Speeches are also spoken, but they’re often written in advance, without the pressure of immediacy, so the author would have time to reach for a thesaurus. I predict speeches will have an Anglo-Saxon/non-Anglo-Saxon profile closer to that of fiction than of either of the extremes in this data. It might vary dramatically based on speaker and audience, so I’ll have to choose a broad sample to smooth out biases.
I would also like to work with the American National Corpus.
Stay tuned, and let me know in the comments if you have observations or suggestions!



